Nested Loops in Bash - A Beginner's Guide

In Bash scripting, nested loops are similar to having a powerful tool for handling complex data processing tasks. They allow you to navigate through layers of data effortlessly, automating repetitive operations and increasing your workflow efficiency. Nested loops are the versatile tools you can rely on, to get the job done. They bring order to complexity and automation to your workflow.
From organizing files in directories to counting students' scores in different classes, nested loops prove invaluable in a wide range of scenarios. Furthermore, we will explore nested loops in the context of multidimensional arrays, demonstrating how they enable the simulation of structured data grids and facilitate efficient data manipulation.
This blog aims to provide a comprehensive understanding of nested loops in Bash scripting, offering insights into their utility and their potential to elevate scripting practices.
Lets get started!
Table of contents
- Understanding Nested Loops in Bash
- Nested for loop
- Nested while loop
- Working with Multidimensional Arrays in Nested Loops
- Nested Loops for Automating Data Tasks
- Conclusion
Understanding Nested Loops in Bash
In Bash, a nested loop is a loop construct where one loop is placed inside another loop. This allows you to perform repetitive tasks with multiple levels of iteration. Nested loops are useful when you need to work with combinations, permutations, or nested data structures in Bash scripting.
Imagine you have a directory with numerous subdirectories, each containing a variety of files. Your task is to automate the process of organizing these files into new folders based on their content types, such as images, documents, or videos. To accomplish this, you can utilize nested loops in your Bash script.
parent_directory="/path/to/parent_directory"
for sub_directory in "$parent_directory"/*; do
if [ -d "$sub_directory" ]; then
category=$(basename "$sub_directory")
mkdir -p "$parent_directory/$category"
for file in "$sub_directory"/*; do
if [ -f "$file" ]; then
file_type=$(file -b --mime-type "$file" | cut -d/ -f1)
mv "$file" "$parent_directory/$category"
fi
done
fi
done
This Bash script organizes files in a main directory. It goes through each subdirectory (which are like folders within the main folder), checks if it's a folder, and then creates a new folder inside the main directory with the same name as the subdirectory. Next, it moves files from the subdirectory to the corresponding new folder based on their type (e.g., images, documents). It identifies the type using the file's format and puts them in the right place. This helps keep your files neatly organized.
Nested for loop
A for loop in Bash is a control structure that facilitates the iterative execution of a specific set of commands or a code block. It allows for repetitive tasks, which could involve iterating through an array or performing batch operations. The primary objective of a "for loop" is to streamline the execution of a series of actions that need to be repeated.
On the other hand, a nested for loop refers to the incorporation of one for loop within another. This construct enables more intricate and structured iterations by introducing multiple layers of looping. In a nested for loop, the inner loop completes its execution for each iteration of the outer loop. This feature proves particularly advantageous when handling tasks that entail combinations, permutations, and the processing of multi-dimensional data.
Consider an example where you want to print a multiplication table from 1 to 5. You can use a nested for loop to accomplish this,
for i in {1..5}; do
for j in {1..5}; do
product=$((i * j))
echo -n "$product "
done
echo
done
Nested while loop
A while loop evaluates a condition initially, executes its block if true, then re-evaluates the condition. This process continues until the condition eventually becomes false. Once the condition is false, the loop terminates, and program control proceeds to the next line of code following the loop.
Nested while loops are used to create loops within loops, enabling intricate control flow. They prove especially valuable when handling multidimensional data structures or executing repetitive tasks with changing conditions.
Here's a Bash script that counts the number of students who scored above a certain threshold in different classes using nested while loops,
#!/bin/bash
# Declare a 2D array using a string with a delimiter
classes=(
"85 92 78 88 95"
"75 80 92 89 78"
"90 88 91 87 82"
)
threshold=85
total_above_threshold=0
# Loop through each class
for class_scores in "${classes[@]}"; do
# Split the class scores string into an array
IFS=" " read -ra scores <<< "$class_scores"
# Loop through the student scores in the class
for score in "${scores[@]}"; do
if [ "$score" -gt "$threshold" ]; then
total_above_threshold=$((total_above_threshold + 1))
fi
done
done
echo "Total students who scored above $threshold: $total_above_threshold"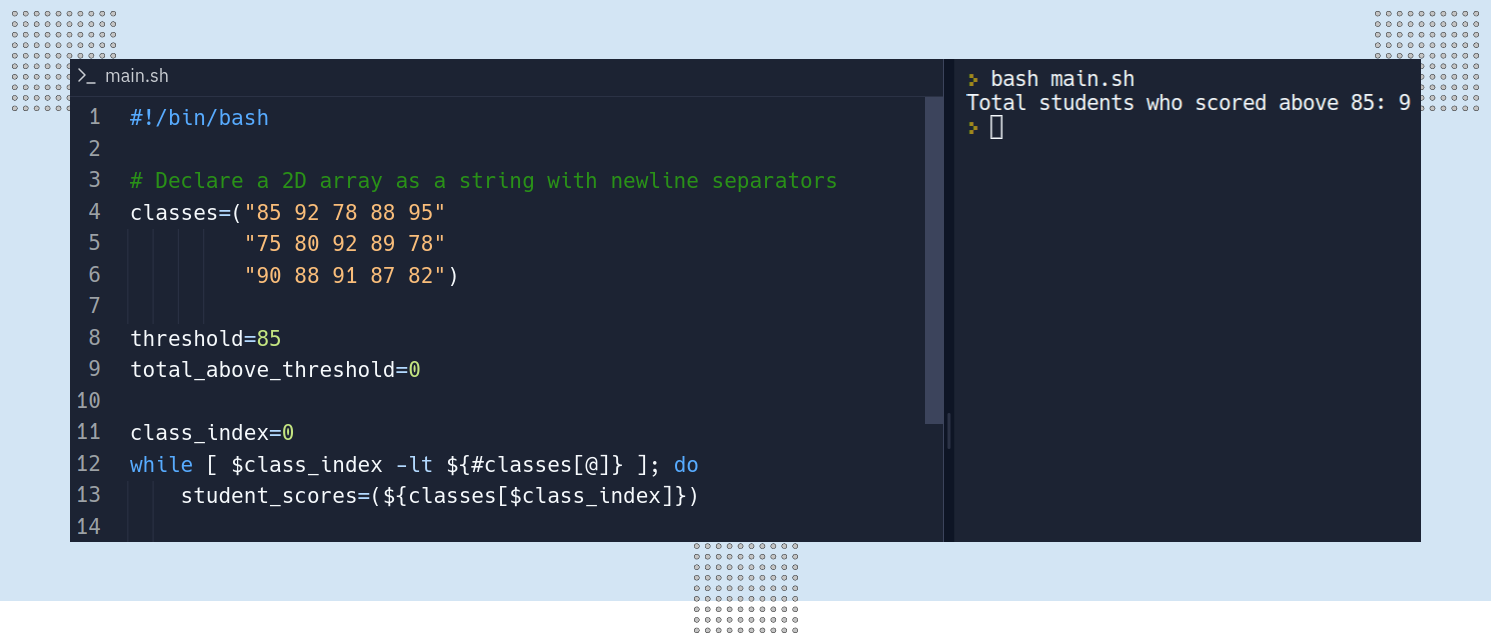
In this example, we are dealing with an array called classes, which serves as a representation of various classes, each of them containing a list of student scores. The script employs a nested while loop structure for processing this data.
The outer while loop is responsible for iterating through each class in the classes array, allowing us to access the individual student scores within each class. Inside the outer loop, we have an inner while loop that iterates through the scores of the students in the current class.
Within the inner loop, the script evaluates whether each student's score exceeds a predetermined threshold. If a student's score is found to be above the specified threshold, the total_above_threshold variable is incremented to keep a running count of such students. This enables the script to tally the number of students who achieved scores above the threshold for each class.
Finally, after processing all the classes and their respective students, the script concludes by printing out the cumulative count of students who scored above the specified threshold.
This script provides a practical example of how nested while loops can be used to manipulate data and compute results, in this case, the number of students meeting a specific performance criterion across different classes.
Working with Multidimensional Arrays in Nested Loops
In Bash, a multidimensional array within nested loops is like organizing data in a grid or table. It is a way to store information in rows and columns. However, Bash doesn't directly support this, so we use associative arrays (like dictionaries) to simulate it. Nested loops are used to go through the rows and columns of this simulated grid, allowing us to work with and manipulate the data efficiently.
Step 1: Declare and Initialize the Array
Begin by defining an associative array using the declare -A command. Then, fill this array with values to replicate a multidimensional structure.
declare -A matrix
matrix[0,0]="A"
matrix[0,1]="B"
matrix[0,2]="C"
matrix[1,0]="D"
matrix[1,1]="E"
matrix[1,2]="F"
Say for example, here we have created an associative array called matrix and filled it with values to simulate a 2x3 matrix. Each element in the above matrix is associated with a unique key like 0,0 for the top-left element, 0,1 for the element to its right, and so on.
Step 2: Determine the Dimensions
Find out how many rows and columns your simulated array has. This information is crucial for efficiently navigating through the data.
rows=2
cols=3
Here, we have set the variables for rows and cols to represent the number of rows (2) and columns (3) in our simulated matrix. Knowing this dimensions helps us to navigate through the data effectively.
Step 3: Nested Loops for Iteration
Employ nested loops to move through the simulated multidimensional array. One loop handles rows, while the other handles columns.
for ((i = 0; i < rows; i++)); do
for ((j = 0; j < cols; j++)); do
echo "Element at ($i, $j) is ${matrix[$i,$j]}"
done
done
In this step, we have employed nested loops. The outer loop (i) iterates over rows, and the inner loop (j) iterates over columns. Inside the loops, we can access and print each element of the matrix using its corresponding key.
Step 4: Manipulate Data
Within the nested loops, you have the flexibility to read, modify, or perform various actions on the array elements.
for ((i = 0; i < rows; i++)); do
for ((j = 0; j < cols; j++)); do
matrix[$i,$j]="NewValue"
done
done
As mentioned earlier that you have the flexibility to interact with the array elements. In this stage, you can change each element by assigning it a new value. You can also carry out a range of operations or calculations on the elements in the array.
Step 5: Customize as Needed
Customize the code according to your specific requirements. You can adjust the array's values, dimensions, or implement different operations within the nested loops as per your needs.
rows=3
cols=4
for ((i = 0; i < rows; i++)); do
for ((j = 0; j < cols; j++)); do
done
done
Nested Loops for Automating Data Tasks
Automation of data processing have become a major aspect of modern computing, streamlining tasks by reducing manual intervention and human error. It involves the creation of scripts or programs to handle various data-related operations automatically.
In Bash scripting, nested loops are like a special tool that helps make complex tasks easier. They work well when you have lots of data organized in different layers. Using nested loops is like having a helper that can go through all the data and do the work for you. This makes things faster and stops you from having to do everything manually, making your work more efficient.
Consider that you have a directory structure where each subdirectory contains a set of files with random names, and you want to rename all these files systematically. Here, in this case we can use nested loops in Bash scripting to automate the process of renaming multiple files located in different directories.
#!/bin/bash
main_directory="/path/to/main_directory"
for subdirectory in "$main_directory"/*; do
if [ -d "$subdirectory" ]; then
echo "Entering directory: $(basename "$subdirectory")"
file_counter=1
for file in "$subdirectory"/*; do
if [ -f "$file" ]; then
new_filename="file_${file_counter}.txt"
mv "$file" "$subdirectory/$new_filename"
echo "Renamed: $(basename "$file") to $new_filename"
((file_counter++))
fi
done
fi
doneIn the above code example, the variable main_directory is used to specify the path where the subdirectories with files are located. The outer loop iterates through each of the subdirectories within the main_directory. The inner loop checks if the item is a regular file using [ -f "$file" ] to avoid processing directories or other types of files.
A new filename (new_filename) is defined for each file in this example by adding a prefix ("file_") followed by a counter. The mv command is then used to rename the file with the new name. The script provides feedback by printing both the old and new file names.
Conclusion
Nested loops in Bash are like loops within loops, making them handy for tricky tasks and complex data handling. To use nested loops effectively, it is crucial to keep your code clear and organized. This means using understandable variable names and proper spacing to make your script easy to read and collaborate on. Testing and fixing errors are vital steps when working with nested loops. Debugging nested loops can be tough, so testing your code with different inputs and using tools like echo statements can help you find and solve problems.
Also, think about efficiency, especially with big sets of data. Try to avoid unnecessary loops and make your loops work efficiently to make your Bash scripts faster and more effective.
I hope this blog has provided you with valuable insights about nested loops in Bash. By now, you should have a clear understanding of their power in handling complex tasks and data structures, as well as the importance of maintaining code clarity, rigorous testing, and optimization for efficiency.
Monitor Your Entire Application with Atatus
Atatus is a Full Stack Observability Platform that lets you review problems as if they happened in your application. Instead of guessing why errors happen or asking users for screenshots and log dumps, Atatus lets you replay the session to quickly understand what went wrong.
We offer Application Performance Monitoring, Real User Monitoring, Server Monitoring, Logs Monitoring, Synthetic Monitoring, Uptime Monitoring, and API Analytics. It works perfectly with any application, regardless of framework, and has plugins.
Atatus can be beneficial to your business, which provides a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
If you are not yet an Atatus customer, you can sign up for a 14-day free trial.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More


