The Evolution of Observability: From StatsD to OpenTelemetry and Beyond

Observability has evolved from simple system monitoring to a comprehensive discipline, blending metrics, logs, and traces into unified insights. Today, it is the backbone of modern infrastructure management and application performance optimization. As we move forward, the integration of AI and security into observability platforms is shaping the future, making them more proactive, intelligent, and robust.
This blog will trace the evolution of observability, examine data formats used by prominent tools and standards like StatsD, Prometheus, OpenTelemetry, OpenMetrics, and vendor platforms like Datadog, New Relic, Atatus, and CloudWatch, and discuss the transformative potential of AI and security.
Table of Contents:
- The evolution of observability
- Key observability standards and their data formats
- The future of observability
- Why observability matters more than ever?
- Monitor your entire application with Atatus
The evolution of observability

- Early Days: Basic Monitoring with StatsD
StatsD, introduced by Etsy, pioneered metrics collection with a lightweight, text-based protocol. Its simplicity made it ideal for basic application monitoring. However, it lacked support for distributed systems and complex queries. - Prometheus and Metrics-Centric Observability
Prometheus revolutionized monitoring by introducing a queryable time-series database and a robust text-based exposition format. Its pull-based model and alerting rules made it a favourite for cloud-native environments. - OpenTelemetry: Unified Observability
OpenTelemetry (OTel) emerged as a unified standard for metrics, logs, and traces. By supporting multiple formats and protocols, OTel provides a vendor-neutral way to instrument applications and transmit telemetry data. - Vendor Platforms: All-in-One Observability
Vendors like Datadog, New Relic, Atatus, and CloudWatch offer all-in-one observability solutions. These platforms integrate data collection, storage, analysis, and visualization, often leveraging AI for anomaly detection and predictive insights.
Key observability standards and their data formats
1. StatsD
A plain-text protocol designed for simplicity.
Format:
<metric_name>:<value>|<type>|@<sample_rate>|#<tags>
- metric_name: The name of the metric (e.g.,
app.requests.count). - value: The numeric value of the metric (e.g.,
100). - type: The metric type (
cfor counter,gfor gauge,msfor timer, etc.). - sample_rate (optional): The sampling rate (e.g.,
@0.1for 10% sampling). - tags (optional): Key-value pairs for additional metadata (e.g.,
#env:prod,region:us-east).
Example:
app.requests.count:100|c|@0.1|#env:prod,region:us-east
2. Prometheus
A text-based exposition format with label support, also compatible with OpenMetrics.
Text Format: Each metric is represented as a line in the following format:
<metric_name>{<label_name>=<label_value>,...} <value> <timestamp>
- metric_name: Name of the metric (e.g.,
http_requests_total). - label_name/label_value: Optional key-value pairs for metadata (e.g.,
method="GET",status="200"). - value: The metric value (e.g.,
12345). - timestamp (optional): Unix timestamp in milliseconds.
Example:
http_requests_total{method="GET",status="200"} 12345 1693195200000
Prometheus Protobuf Format:
Prometheus also supports protobuf for binary representation, used when integrating with APIs like remote_write for more efficient data transmission.
3. OpenTelemetry
A unified framework supporting JSON and protobuf for metrics, logs, and traces. OpenTelemetry defines unified data formats for metrics, logs, and traces, typically serialized as JSON or protobuf. It is designed to support both in-memory transmission and external export.
OpenTelemetry Metrics (JSON):
{
"resource": {
"attributes": {
"service.name": "my-service",
"env": "production"
}
},
"instrumentationLibraryMetrics": [
{
"instrumentationLibrary": {
"name": "example-metrics"
},
"metrics": [
{
"name": "http_requests_total",
"description": "Total number of HTTP requests",
"unit": "1",
"sum": {
"dataPoints": [
{
"attributes": {
"method": "GET",
"status": "200"
},
"value": 1000,
"timeUnixNano": 1693195200000000000
}
],
"aggregationTemporality": "AGGREGATION_TEMPORALITY_CUMULATIVE"
}
}
]
}
]
}
OpenTelemetry Traces (JSON):
{
"resourceSpans": [
{
"resource": {
"attributes": {
"service.name": "my-service"
}
},
"scopeSpans": [
{
"scope": {
"name": "example-instrumentation"
},
"spans": [
{
"traceId": "4bf92f3577b34da6a3ce929d0e0e4736",
"spanId": "00f067aa0ba902b7",
"name": "GET /api",
"kind": "SPAN_KIND_SERVER",
"startTimeUnixNano": 1693195200000000000,
"endTimeUnixNano": 1693195205000000000,
"attributes": {
"http.method": "GET",
"http.status_code": 200
}
}
]
}
]
}
]
}
4. OpenMetrics
Enhances Prometheus' format with support for exemplars and extended metadata.
Format:
# TYPE http_requests_total counter
http_requests_total{method="GET",status="200"} 12345 # {trace_id="abc123"}
Key differences from Prometheus:
- Support for exemplars (e.g.,
{trace_id="abc123"}). - Extended metadata for metrics.
5. CloudWatch: JSON API for metrics ingestion
{
"MetricData": [
{
"MetricName": "CPUUtilization",
"Dimensions": [{"Name": "InstanceId", "Value": "i-1234567890abcdef0"}],
"Value": 75.5
}
],
"Namespace": "AWS/EC2"
}
The future of observability
1. AI-Driven insights
Artificial Intelligence is transforming observability from reactive monitoring to proactive management. Here’s how:
- Anomaly Detection: AI models analyse historical data to identify unusual patterns in real-time.
- Predictive Maintenance: AI forecasts potential issues, enabling preventive resolution.
- Root Cause Analysis: By correlating telemetry data, AI accelerates the identification of root causes.
2. Security meets observability
As systems become more complex, integrating security into observability is critical.
- Threat Detection: Observability platforms can monitor unusual access patterns or data exfiltration attempts.
- Compliance Auditing: Logs and traces serve as evidence for compliance with regulations like GDPR and PCI DSS.
- End-to-End Encryption: Ensures telemetry data is secure in transit and at rest.
3. The rise of unified standards
Tools like OpenTelemetry and OpenMetrics are pushing the industry towards vendor-neutral solutions. These standards simplify instrumentation, foster interoperability, and reduce vendor lock-in.
Why observability matters more than ever?
Modern systems are distributed, ephemeral, and dynamic. Observability is no longer optional, it’s a necessity. By embracing open standards, leveraging AI, and integrating security, organizations can ensure their applications are reliable, performant, and secure.
The future of observability is about more than just monitoring. It’s about empowering teams to anticipate issues, respond faster, and build systems that users trust.
The evolution of observability has been remarkable, from the simplicity of StatsD to the comprehensiveness of OpenTelemetry and vendor platforms. As we move into an AI-driven future, observability will be the key factor of modern infrastructure, seamlessly blending performance, reliability, and security.
Are you ready to take your observability game to the next level? Choose tools and standards that align with your goals, and let AI and security guide your journey into the future.
Monitor your entire application with Atatus
Atatus is a Full Stack Observability Platform that lets you review problems as if they happened in your application. Instead of guessing why errors happen or asking users for screenshots and log dumps, Atatus lets you replay the session to quickly understand what went wrong.
We offer Application Performance Monitoring, Real User Monitoring, Server Monitoring, Logs Monitoring, Synthetic Monitoring, Uptime Monitoring, and API Analytics. It works perfectly with any application, regardless of framework, and has plugins.
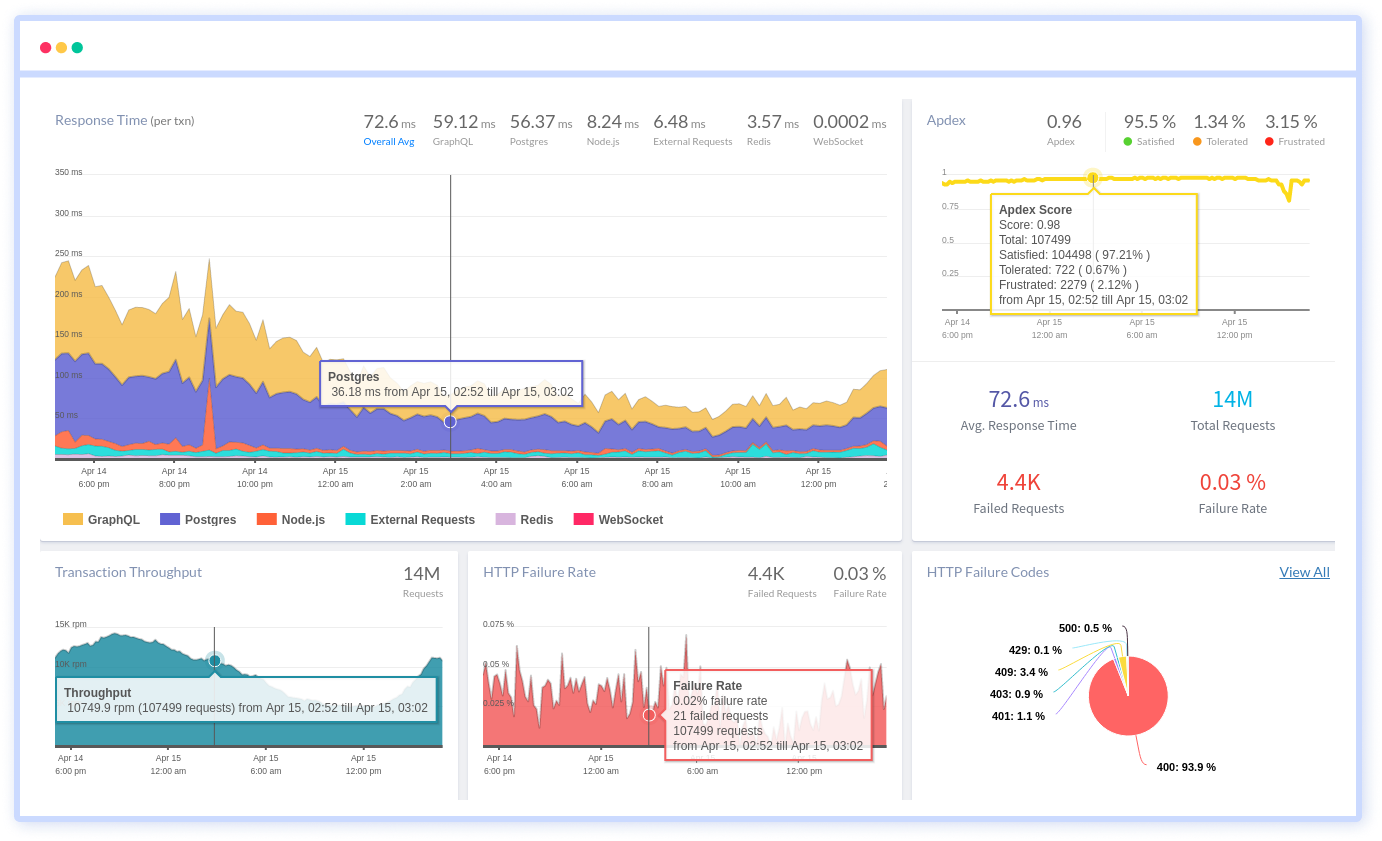
Atatus can be beneficial to your business, which provides a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
If you are not yet an Atatus customer, you can sign up for a 14-day free trial.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More

![New Relic vs Splunk - In-depth Comparison [2026]](/blog/content/images/size/w960/2024/10/Datadog-vs-sentry--19-.png)
![New Relic vs Sentry - Which Monitoring Tool to Choose? [2026]](/blog/content/images/size/w960/2024/10/VS--1-.png)