Database Sharding: What is it, and How it Works?

Today’s world runs on data. We are constantly improving our solutions thanks to the plethora of data available to us in the public domain. Our society has seen a behavioral change when it comes to formulating remedies. We are increasingly adopting data-driven decisions, and rightly so.
Now, talking about this whole data logic, where do you think this enormous amount of data gets stored? Well, the answer is a database!
As our content consumption has increased manifold in the past years, our databases had to be scaled up in shorter spans than ever. As a result, we have begun to consider other options for improving scalability and availability of these databases.
Before we get into Sharding, you must know why we had to adopt this practice. Here are some pointers:
- Traditional databases often rely on a single server or a tightly coupled cluster of servers to handle all data and queries. As the workload grows, a single server will not be able to handle all the data that is coming in. The querying time increases, and responses become slower.
- Managing backups and ensuring data integrity also becomes more complex and time-consuming as the data volume expands.
- You would have noticed that traditional databases often rely on a single server or a limited number of replicas for data storage. This architecture poses a risk of single points of failure, where the failure of a single server can render the entire database inaccessible.
- Scaling traditional databases can be costly, especially when vertical scaling is no longer sufficient and horizontal scaling options are limited. Vertical scaling, which involves adding more resources to a single server (e.g., increasing CPU, memory, or storage capacity), has limitations. Eventually, a point is reached where further vertical scaling becomes impractical or too costly.
- Maintaining data consistency across a distributed system can be complex in traditional databases. Ensuring atomicity, consistency, isolation, and durability (ACID properties) across multiple servers can pose challenges, especially during distributed transactions or when replication mechanisms are involved.
Addressing these challenges typically involves exploring alternative approaches such as sharding, distributed databases, or adopting cloud-based database services. These methods ensure high availability and practical scalability.
And this blog will tell you why you must adopt sharding and how you can do so.
Table Of Contents:-
- What is Database Sharding?
- How Sharding differs from traditional database architectures?
- Sharding Implementation
- Challenges and Considerations about Sharding
- Sharding Frameworks and their usage in real-world Examples
What is Database Sharding?
Database Sharding is a technique used to horizontally partition a database into smaller, more manageable pieces called shards.
In Sharding, the data in a database is distributed across multiple servers or nodes, each responsible for a specific subset of the data. This approach allows for improved scalability, performance, and availability in large-scale database systems.
In a sharded database, the data is divided based on a predefined shard key, which is a chosen attribute or value that determines the shard to which a particular data record belongs. By distributing the data across multiple shards, each shard can handle a subset of the workload, enabling parallel processing and reducing the burden on individual servers.
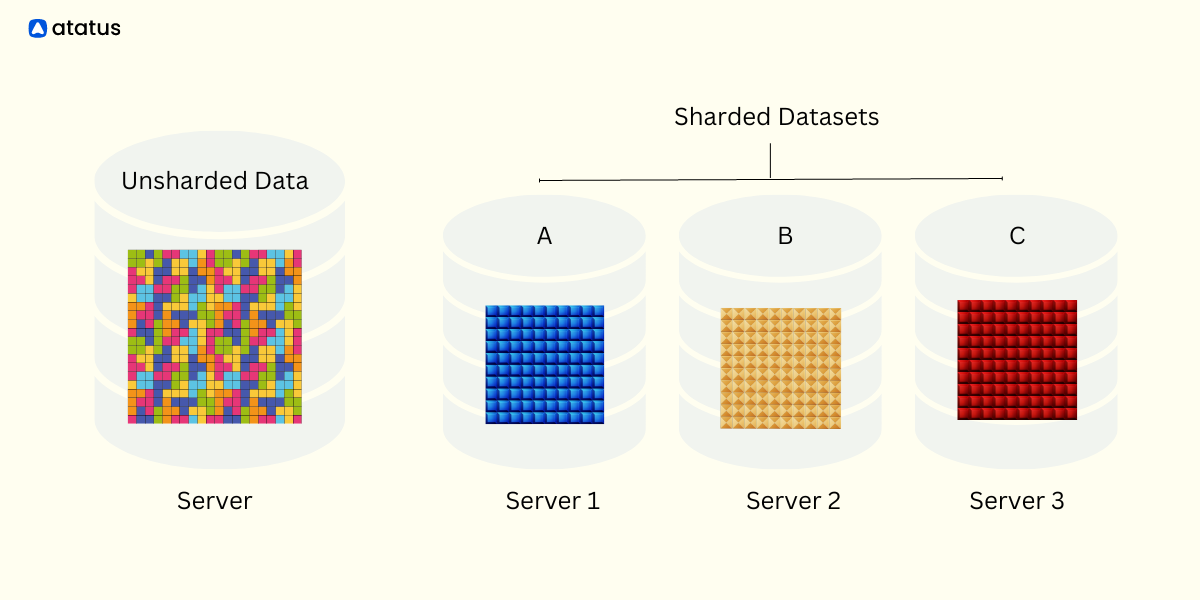
The main goal of database sharding is to overcome the limitations of traditional single-server databases, which can become bottlenecks as the data and traffic volume increase. Sharding enables databases to handle higher data loads and provide faster response times by leveraging the collective processing power of multiple servers.
Sharding offers several benefits, including:
- Scalability: Sharding allows for horizontal scaling, where additional servers can be added to the database infrastructure to accommodate increased data and traffic.
- Performance: By distributing the data and workload, sharding improves read and write performance, as each shard handles a smaller portion of the data, reducing contention.
- Availability: Sharding enhances fault tolerance and availability. If one shard fails, the other shards can continue to operate, reducing the impact on the overall system.
- Flexibility: Sharding enables targeted optimization for specific types of data, allowing different shards to use different hardware or configurations based on their requirements.
However, sharding also introduces some challenges, such as maintaining data consistency across shards, handling distributed transactions, and managing complex query execution across multiple shards.
These challenges require careful planning, proper shard key selection, and effective data distribution strategies to ensure a successful implementation of sharding in a database system. And we will be discussing about these in the next few sections.
Sharding Example
Here's an example demonstrating how horizontal sharding works in practice with a store table before sharding:
Assume we have a store table in a database that stores information about products. The table is structured as follows:
| product_id | product_name | price | quantity | category |
|---|---|---|---|---|
| 1 | Product A | 10.99 | 11 | Electronics |
| 2 | Product B | 13.65 | 16 | Clothing |
| 3 | Product C | 12.90 | 30 | Electronics |
| 4 | Product D | 132.72 | 5 | Home |
| 5 | Product E | 10.11 | 70 | Clothing |
This store table contains product information such as product ID, product name, price, quantity, and category.
Now, let's assume we want to shard the store table horizontally based on the category column.
After horizontal sharding, the store table is divided into multiple shards based on the chosen sharding key. Each shard will contain a subset of data that belongs to a specific category.
For example, after horizontal sharding, the store table might be divided into the following shards:
Shard 1 - Electronics
| product_id | product_name | price | quantity | category |
|---|---|---|---|---|
| 1 | Product A | 10.99 | 11 | Electronics |
| 3 | Product C | 12.90 | 30 | Electronics |
Shard 2 - Clothing
| product_id | product_name | price | quantity | category |
|---|---|---|---|---|
| 2 | Product B | 13.65 | 16 | Clothing |
| 5 | Product E | 10.11 | 70 | Clothing |
Shard 3 - Home
| product_id | product_name | price | quantity | category |
|---|---|---|---|---|
| 4 | Product D | 132.72 | 5 | Home |
How Sharding differs from Traditional Database Architectures?
Sharding differs from traditional database architectures in several key aspects. Let’s try and understand them.
1. Data Distribution
In traditional database architectures, all data resides on a single server or a tightly coupled cluster of servers. In contrast, sharding involves horizontally partitioning the data and distributing it across multiple servers or nodes called shards. Each shard contains a subset of the data, allowing for parallel processing and improved scalability.
2. Scalability
Traditional databases often face challenges in scaling as the data volume and traffic increase. Scaling vertically by adding more resources to a single server has limitations. Sharding, on the other hand, enables horizontal scalability by adding more shards to the database infrastructure. This distributed approach allows for better handling of large datasets and high transaction volumes.
3. Query Performance
In traditional databases, as the data size grows, the performance of queries can deteriorate due to the increased workload on a single server. Sharding mitigates this issue by distributing the data across multiple shards. Queries can be executed in parallel on different shards, leading to improved query performance and reduced response times.
4. Availability and Fault Tolerance
Traditional databases typically rely on a single server or a limited number of replicas for data storage. If that server fails, the entire database becomes inaccessible. Sharding, on the other hand, improves availability and fault tolerance. If one shard goes down, the other shards can continue to function, ensuring that the database remains accessible.
5. Data Consistency and Transactions
Maintaining data consistency and handling distributed transactions can be challenging in sharded databases. Traditional databases provide strong transactional guarantees within a single server, but in sharded environments, distributed transactions require additional considerations and techniques to ensure data integrity and consistency across shards.
6. Shard Management
Sharding introduces the need for managing the shards, including provisioning, deployment, and rebalancing of data. Traditional databases do not have this level of complexity since all data resides on a single server. Shard management involves strategies for distributing data, monitoring shard performance, and dynamically adding or removing shards as needed.
Sharding Architecture
There are various types of sharding architectures, including key-based sharding, directory-based sharding, and range-based sharding. Let's explore each of these in more detail:
1. Key-Based Sharding
Key-based sharding also known as hash-based sharding, involves partitioning based on a key value. Each data item is associated with the unique key, and a hash function is applied to the key to determine the shard where the data will be stored.
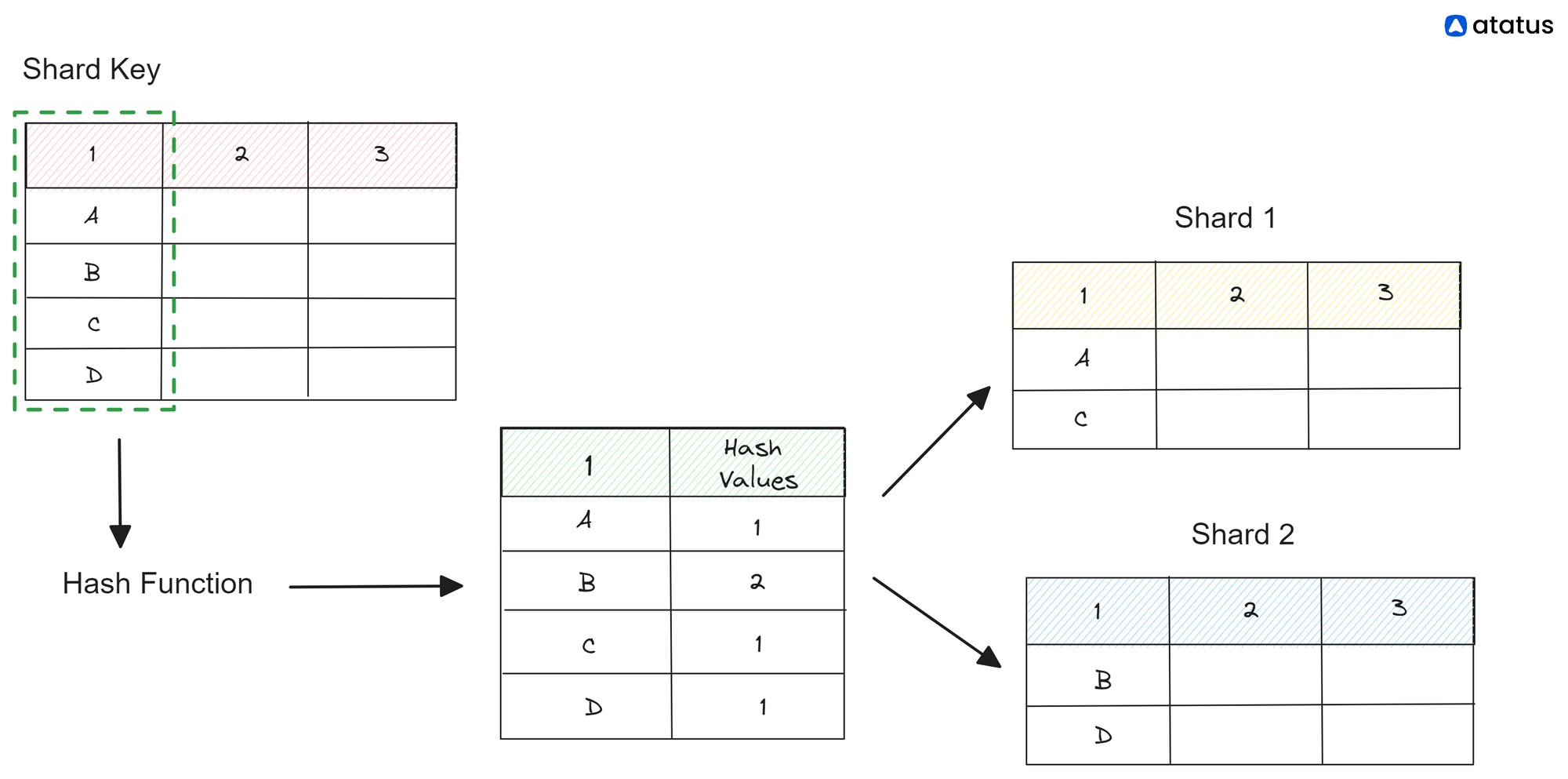
The data is evenly distributed across multiple shards using the hash function, ensuring a balanced distribution of workload and storage. This approach is commonly used when the access pattern is based on the key value, and there is no specific requirement for data range or locality.
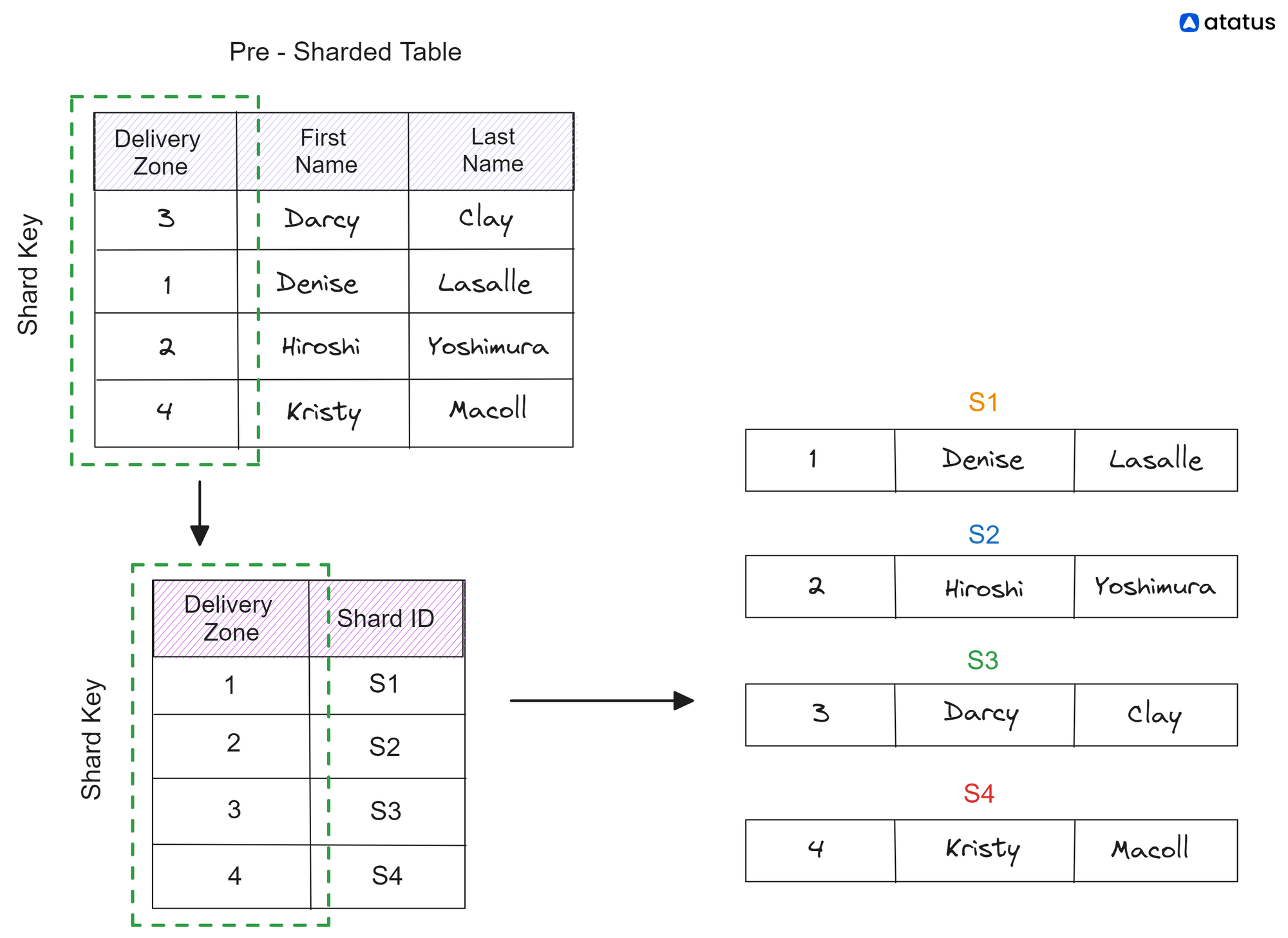
2. Directory-Based Sharding
Directory-based sharding, also referred to as metadata-based sharding, involves the use of a central directory or metadata service that maps data items to their corresponding shards. The directory maintains the mapping information, such as the shard identifier or location, for each data item.
When a client wants to access or modify a specific data item, it first consults the directory to obtain the shard information and then communicates directly with the corresponding shard. This approach provides flexibility in managing shard locations and allows for dynamic changes in the shard configuration.
3. Range-Based Sharding
Range-based sharding divides the data based on a specific range or criterion. Instead of using a key or hash function, the data is partitioned based on a defined range of values.
For example, in a system storing user data, the data might be divided based on the user's last name, where each shard handles a specific range of last names (e.g., A-F, G-M, N-Z).
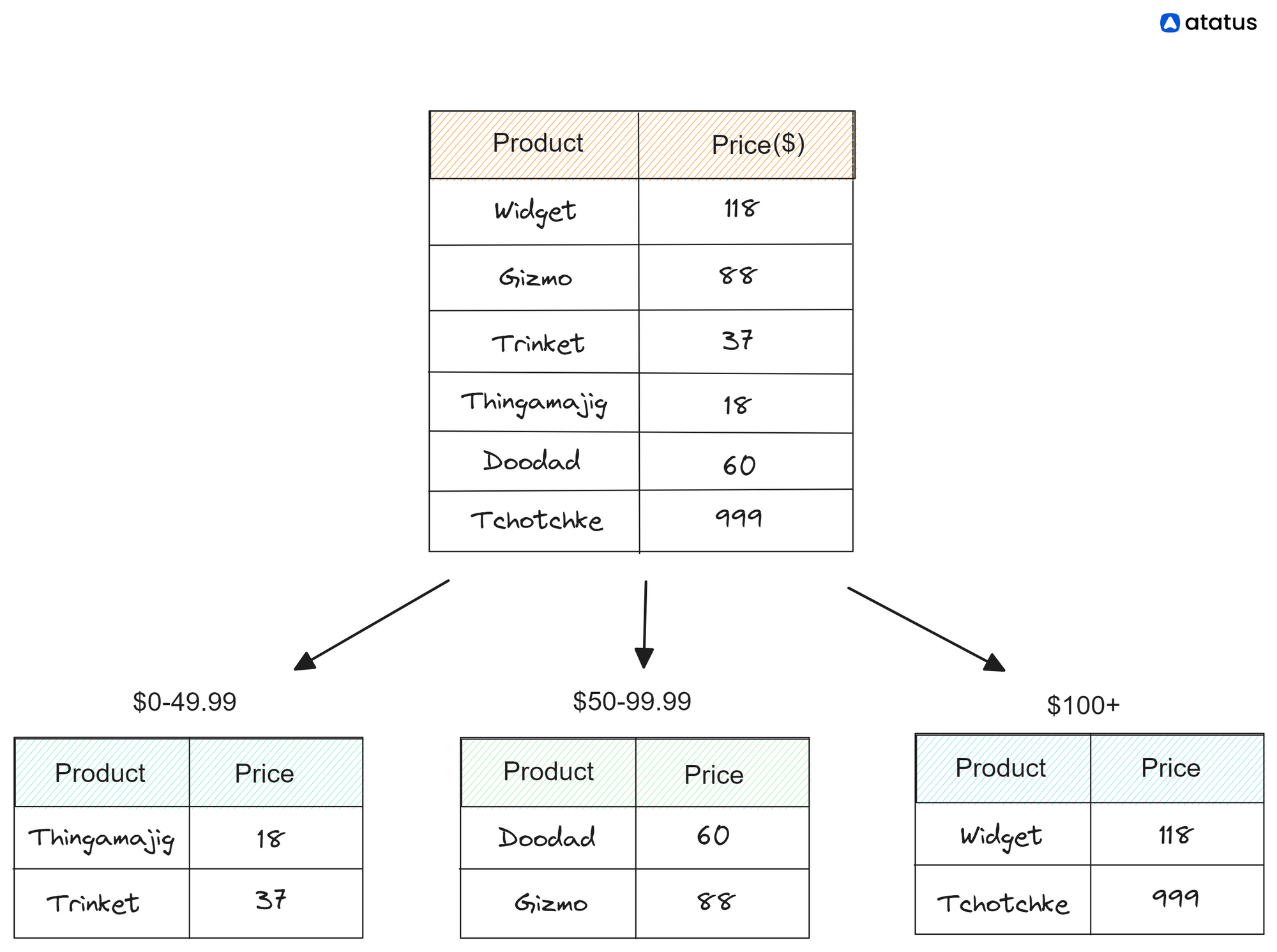
This approach is useful when there is a natural ordering or range-based access pattern in the data. It can help optimize queries that involve range-based operations, such as retrieving all data within a certain range.
Sharding Implementation
Implementing Sharding involves several key steps, including shard key selection, distributing data across shards, query execution and routing, and monitoring and optimizing performance. Let's explore each step in detail:
1. Shard Key Selection
Choose an appropriate shard key that determines how data will be distributed across shards. The shard key should ideally exhibit the following characteristics:
- The shard key should have a wide range of unique values to evenly distribute the data across shards.
- The shard key should result in a balanced distribution of data, avoiding hotspots where one shard becomes overloaded.
- Consider the common query patterns and how they align with the shard key. The shard key should support efficient querying and minimize the need for cross-shard operations.
2. Distributing Data Across Shards
Determine the distribution strategy to divide the data among the shards. Common approaches include:
- Range-Based Sharding: Dividing the data based on a range of values in the shard key. For example, one shard may handle customers with IDs from 1 to 1000, while another shard handles IDs from 1001 to 2000.
- List-Based Sharding: Dividing the data based on predefined lists or ranges of values in the shard key. This approach allows for more control over the distribution of specific data subsets.
- Hash-Based Sharding: Applying a hashing function to the shard key to determine the shard assignment. This approach provides a random distribution of data and avoids potential skew or hotspots.
3. Query Execution and Routing
Develop mechanisms to handle query execution and routing in a sharded environment:
- Query-Based Routing: Determine which shard(s) hold the required data based on the shard key included in the query. The query router directs the query to the appropriate shard(s) for execution.
- Scatter/Gather: For queries that span multiple shards, the scatter/gather technique is used. The query is divided into sub-queries that are sent to the relevant shards, and the results are combined and returned.
4. Monitoring and Optimizing Shard Performance
Establish monitoring and optimization practices to ensure efficient sharding performance:
- Track the performance metrics of each shard, including latency, throughput, and resource utilization. Identify any performance bottlenecks or imbalances among shards.
- Regularly monitor shard workloads and redistribute data if necessary to maintain balanced utilization across shards. Load balancing helps prevent hotspots and ensures even distribution of queries and data.
- Analyze query patterns and optimize them for sharded environments. Consider techniques like denormalization, caching, or using appropriate indexing strategies to improve query performance across shards.
Remember, implementing Sharding requires careful planning, consideration of the data model, and understanding the workload patterns. It is important to test and iterate on the Sharding implementation to ensure optimal performance and scalability for your specific use case.
Challenges and Considerations about Sharding
We had earlier talked about how implementing Sharding in a database system introduces several challenges and considerations. Some of those key challenges and considerations have been shared here:
- Maintaining data consistency across shards can be complex, especially during distributed transactions or when updates span multiple shards. Ensuring atomicity, consistency, isolation, and durability (ACID properties) across the distributed system requires careful design and implementation of transaction management mechanisms.
- Queries that involve data from multiple shards (cross-shard queries) can be challenging to execute efficiently. Coordinating and aggregating results from multiple shards can introduce additional complexity and overhead. Optimizing query performance in a sharded environment requires thoughtful query planning and execution strategies.
- Choosing an appropriate shard key is crucial for effective Sharding. The shard key should distribute the data evenly across shards to avoid hotspots or imbalances. Poor shard key selection can result in uneven data distribution, increased cross-shard operations, and degraded performance.
- Uneven data distribution or skewed data access patterns can lead to hotspots, where certain shards receive a disproportionately high volume of traffic. Hotspots can result in performance bottlenecks, decreased scalability, and an uneven utilization of resources. Mitigating data skew and hotspot issues requires careful data distribution strategies and load-balancing mechanisms.
- Performing joins and aggregations across shards can be challenging. Coordinating data from multiple shards to execute these operations efficiently requires careful query planning, data redistribution, or the use of specialized techniques such as parallel query execution or distributed query engines.
- Managing and operating a sharded database system involves additional complexity compared to a traditional database. Provisioning and deploying new shards, rebalancing data across shards, and handling shard failures require robust management tools and processes. Automating shard management tasks can help streamline operations.
- Monitoring the performance and health of individual shards, as well as the overall system, is crucial for identifying bottlenecks, detecting failures, and optimizing performance. Monitoring tools and practices should be implemented to provide visibility into shard performance, data distribution, and query execution.
- As the database evolves, the need for data migration and resharding may arise. Migrating data between shards or adding/removing shards requires careful planning, as it involves redistributing data, managing concurrent operations, and ensuring minimal disruption to ongoing processes.
- Before deploying sharding in production, thorough testing and simulation are necessary to validate the design, measure performance, and identify potential issues. Testing should cover various workload scenarios and failure conditions to ensure the system behaves as expected.
Successfully addressing these challenges requires:
- Careful planning
- Proper design choices
- Effective algorithms
- Data distribution strategies
- Robust monitoring tools
It is important to consider the specific requirements of the application, data access patterns, and expected scalability needs when implementing sharding in a database system.
Sharding Frameworks and Tools with real-world Examples
Sharding has been implemented in various real-world scenarios to address scalability and performance challenges. Let's look at some of these examples -
- Amazon, one of the largest e-commerce platforms, uses sharding to handle its vast product catalog and high transaction volumes. Sharding allows them to distribute product data across multiple shards, ensuring efficient product search and seamless checkout experiences.
- Facebook utilizes sharding to manage its massive user base and handle high volumes of social interactions. Sharding helps distribute user profiles, posts, and messages across shards, enabling efficient access and real-time interactions.
- Riot Games, the creator of League of Legends, uses sharding to handle the immense player base and match data. Sharding allows them to distribute player data, game sessions, and matchmaking across multiple shards, ensuring smooth gameplay experiences.
- PayPal employs sharding to handle its extensive transaction database and ensure fast and reliable payment processing. Sharding helps distribute transaction data, user accounts, and balances across shards, enabling high-performance and scalable financial services.
- Uber relies on sharding to manage its ride request and driver data in real-time. Sharding helps distribute user profiles, ride data, and driver information across shards, ensuring quick matching and efficient service delivery.
- Google Ads leverages sharding to handle its vast ad inventory and billions of ad impressions. Sharding enables the distribution of ad campaign data, user profiles, and targeting information across shards, ensuring efficient ad serving and real-time bidding.
These examples highlight how sharding is applied across different industries to handle large-scale data management and provide scalable and responsive services.
Sharding enables these systems to handle massive data volumes, high traffic loads, and complex query patterns, ensuring optimal performance and user experiences.
Conclusion
I hope you would have got an idea of why managing your database is so important, especially at present when the world is getting more centred around data and its implications.
We have provided you with a beginning on how to adopt sharding (if that's your choice of database management) in this blog. Check out this article on Database Management to learn why DBMS is pertinent to having a healthy system.
Now about sharding, it allows for greater scalability, improved performance, and increased fault tolerance compared to traditional database architectures. However, it also introduces additional complexity in terms of data distribution, query execution, and data consistency management, requiring careful planning and implementation considerations. And that's why we are here with a comprehensive Database Management Solution, check out more on Atatus.
Database Monitoring with Atatus
Atatus provides you an in-depth perspective of your database performance by uncovering slow database queries that occur within your requests, and transaction traces to give you actionable insights. With normalized queries, you can see a list of all slow SQL calls to see which tables and operations have the most impact, know exactly which function was used and when it was performed, and see if your modifications improve performance over time.
Atatus benefit your business, providing a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More